深度学习|Deep Learning
数学基础
常用函数
- sigmoid
- softmax
- relu
损失函数|Loss Function
Cross Entropy Loss|交叉熵损失
NLP|自然语言处理
Embeddings|嵌入
预训练、微调、指令微调|Pre-training、Fine-tuning、Insturct-tuning
In simple terms, pre-training a neural network refers to first training a model on one task or dataset. Then using the parameters or model from this training to train another model on a different task or dataset. This gives the model a head-start instead of starting from scratch.
Now pre-training a neural network entails four basic steps:
- We have a machine learning model $m$ and datasets $A$ and $B$
- Train $m$ with dataset $A$
- Before training the model on dataset $B$, initialize some of the parameters of $m$ with the model which is trained on $A$
- Train $m$ on dataset $B$
Reference: What is pretrainng?
Fine-tuning is where you take an already-pre-trained model and further train it on a more specific dataset. This dataset is typically smaller and focused on a particular domain or task. The purpose of fine-tuning is to adapt the model to perform better in specific scenarios or on tasks that were not well covered during pre-training. The new knowledge added during fine-tuning is more about enhancing the model’s performance in specific contexts rather than broadly expanding its general knowledge.
An example of fine-tuning that I did a few years ago (before ChatGPT changed everything) was to fine-tune GPT-2 on song lyrics. After fine-tuning it on Eminem for example, I could give it a few words and it would generate lyrics in the same style.
Instruct-tuning is a relatively newer concept, used in models like ChatGPT and InstructGPT, where the model is trained (or further trained) to follow instructions in prompts better. This doesn’t necessarily involve adding new factual knowledge to the model; rather, it’s about training the model to understand and execute given instructions more effectively. It’s more about improving the model’s ability to parse and respond to prompts in a way that aligns with user intentions.
OpenAI has a really great demo of this on their “Aligning language models to follow instructions” page..
Reference: What is the difference between pre-training, fine-tuning, and instruct-tuning exactly? - kelkulus
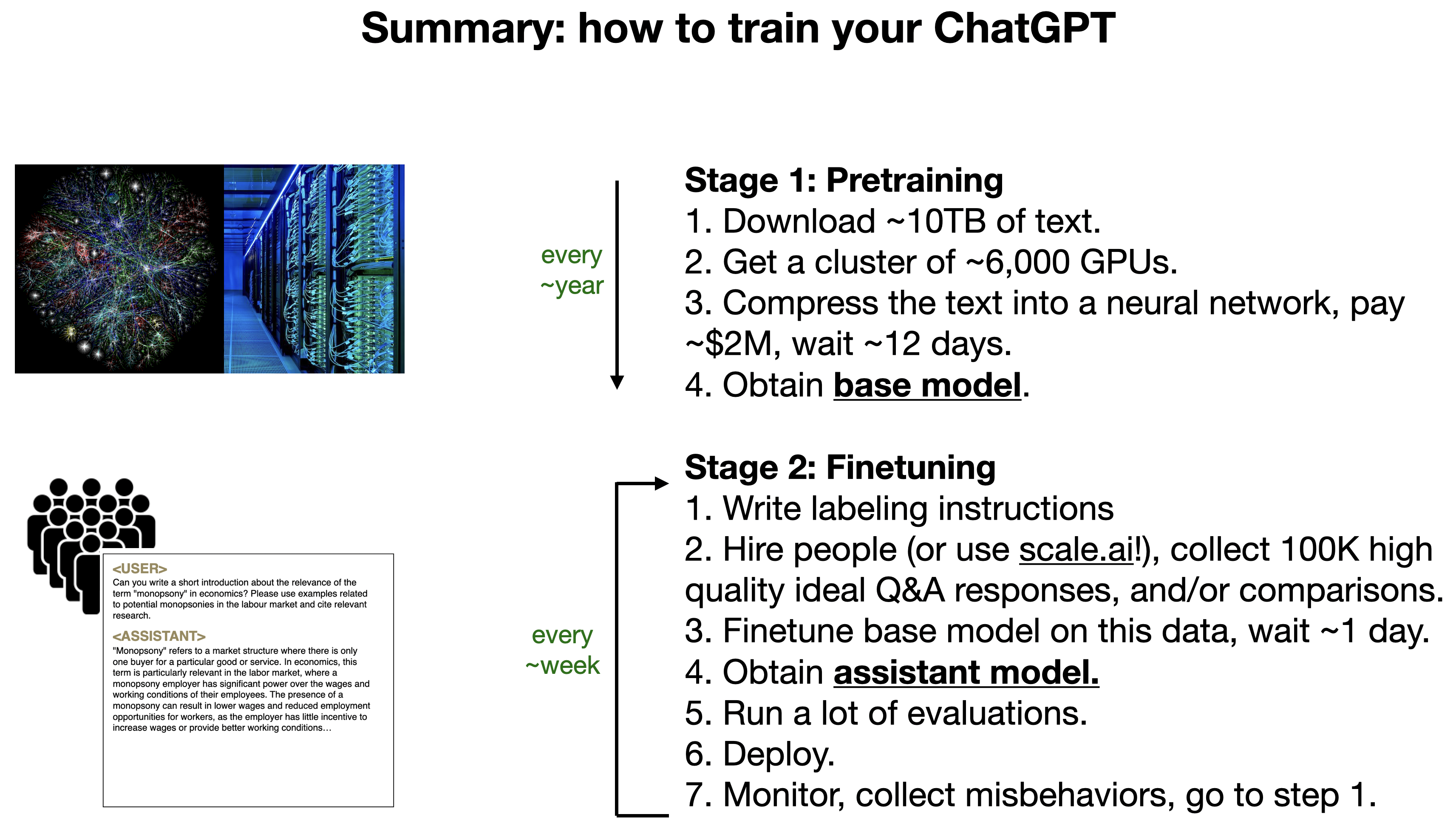
Reference: [1hr Talk] Intro to Large Language Models - Andrej Karpathy
表征学习|Representation Learning
Terms
- representation
- supervised learning
- un-supervised learning
- semi-supervised learning
- weakly-supervised learning
- self-supervised learning
Some Questions
- What is representation?
- Why we need representation?
- What are the problems with hand-designing features ?
- How does deep neural networks learn representations ?
- Why learning generalizable representations from non-annotated data is so important ?
对比学习|Contrastive Learning
需要正样本、负样本的定义。
图神经网络|GNN
图神经网络|Graph neural networks
图对比学习|Graph Contrastive Learning
知识蒸馏|Knowledge Distillation
- 教师模型
- 学生模型
- Soft target
- Hard target
- 带温度的softmax
多模态|MultiModal
多模态的定义
模态是指人接受信息的特定方式,如文字、声音、图像、视频等。来自单一模态的信息无法全面地理解事物,关联来自多种模型的信息能做出更好的判断。
多模态机器学习的主要任务
多模态表示学习(Representation)
- 如何将多个模态数据所蕴含的语义信息数值化为实值向量。
- 联合表示(Joint Representations)和协同表示(Coordinated Representations)
- Joint Representations:将多个模态的信息一起映射到一个统一的多模态向量空间
- Coordinated Representations:将多模态中的每个模态分别映射到各自的表示空间,但映射后的向量之间满足一定的相 关性约束(例如线性相关)。
模态间映射(Mapping)
- 映射也称为转换,负责将一个模态的信息转换/映射为另一种模态。
- 映射任务分类:
- 机器翻译(Machine Translation)
- 图像字幕(Image Captioning)
- 语音合成(Speech Synthesis)
多模态对齐(MultiModal Alignment)
多模态对齐的目标是将不同模态的数据,在特征、语义或表示层面上的匹配与对应。
多模态对齐的目的是使得来自不同模态的输入能够在一个公共表示空间中表达。
分类1
- 基于规则的对齐:依据人为定义的规则来建立模态间的对应关系。
- 基于学习的对齐:使用机器学习方法,特别是深度学习,来自动发现和学习不同模态间的对应关系。
分类2
实际案例
- LLaVA
- LLaVA 的对齐方式相对来说比较简单,只有简单的线性层。
- Flamingo
- Cross-attention
- BLIP-2
- Q-Former w/ Linear Projector
- LLaVA
融合(MultiModal Fusion)
- 主要研究如何整合不同模态间的模型与特征。
- 融合分类
- pixel level:原始数据进行融合
- feature level:对抽象的特征进行融合
- decision level :对决策结果进行融合
协同学习(co-learning)
- 主要研究如何将信息富集的模态上学习的知识迁移到信息匮乏的模态,使各个模态的学习互相辅助。典型的方法包括多模态的零样本学习、领域自适应等
多模态大语言模型的分类
- 按照 任务类型 划分
- 以 多模态输入理解 为主的模型
- 图像-文本(Image-Text):BLIP-2、LLaVA、MiniGPT-4、OpenFlamingo
- 视频-文本(Video-Text):VideoChat、Video-ChatGPT、LLaMA-VID
- 音频-文本(Audio-Text):Qwen-Audio
- 以 多模态输出 为主的模型
- 图像文本(Image-Text):GILL、Kosmos-2、Emu、MiniGPT-5
- 音频文本(Audio-Text):AudioPaLM
- 以 任意模态转换(Any-to-Any)为主的模型
- Visual-ChatGPT、HuggingGPT、AudioGPT
- NExT-GPT、CoDi-2、Moda Verse
- 以 多模态输入理解 为主的模型
- 按照 模型系列 划分
- CLIP系列
- BLIP、BLIP2
- InstructBLIP系列
- LLAVA、LLAVA1.5系列
- Intern-VL系列
- DeepSeek-VL系列
- miniGPT4、miniGPT5系列
- MoE系列
- DiT系列
多模态大语言模型的架构
多模态大语言模型一般由5个组件构成:模态编码器(Modality Encoder)、Input Projector(输入投影器)、大语言模型骨干(LLM Backbone)、Output Projector(输出投影器)、模态生成器(Modality Generator)
- 模态编码器(Modality Encoder, ME)
- 负责将不同模态的输入编码成特征。
- 常见的编码器包括图像的NFNet-F6、ViT、CLIP ViT等,音频的Whisper、CLAP等,视频编码器等。
- 图像:NFNet-F6、ViT、CLIP ViT
- 音频:Whisper、CLAP等
- 输入投影器(Input Projector)
- 负责将其他模态的特征投影到文本特征空间,并与文本特征一起输入给语言模型。
- 常用的投影器包括线性投影器、MLP、交叉注意力等。
- Linear Projector
- MLP
- Cross-Attention
- Q-Former
- P-Former
- 语言模型骨架(LLM Backbone)
- 利用预训练的语言模型,负责处理各种模态的特征,进行语义理解、推理和决策。
- 常用的语言模型包括Flan-T5、ChatGLM、UL2等。
- 输出投影器(Output Projector)
- 负责将语言模型输出的信号转换成其他模态的特征,以供后续模态生成器使用。
- 常用的投影器包括Tiny Transformer、MLP等。
- 模态生成器(Modality Generator, MG)
- 负责生成其他模态的输出。
- 常用的生成器包括图像的Stable Diffusion、视频的Zeroscope、音频的AudioLDM等。
多模态经典模型
CLIP
- clip的原理/训练流程
- CLIP 中具体loss 是什么?
- 多模态模型中文本和图像模态怎么对
齐融合 - CLIP 图像模态输入 size更大精度更高
的图片,怎么处理 - clip 中的正负样本是怎么选择的
BLIP-2
LLaVA
Zero Shot Image Classification
https://medium.com/@Mert.A/zero-shot-image-classification-with-clip-and-huggingface-c73c438fce6d
值得关注的大佬
| 姓名 | 主页 | 亮点 |
|---|---|---|
| Andrej Karpathy | https://karpathy.ai/https://karpathy.ai/ | 曾在OpenAI工作 |


